Non-convex clustering using HDBSCAN#
We have previously mentioned that k-means consists of minimizing the samples euclidean distances to their assigned centroid. As a consequence, k-means is more appropriate for clusters that are isotropic and normally distributed (look like spherical blobs). When this assumption is not met, k-means can lead to unstable clustering results that do not qualitatively match the cluster we seek. On possible way is to use a more general variant of k-means named Gaussian Mixture Models (GMM), which allows for elongated clusters with strong correlation between features as explained in this tutorial of the scikit-learn documentation. However, GMM still assumes that clusters are convex, which is not always the case in practice.
In this notebook we introduce another clustering technique named HDBSCAN, an acronym which stands for “Hierarchical Density-Based Spatial Clustering of Applications with Noise” which further allows for non-convex clusters.
Let’s explain each of those terms. HDBSCAN is hierarchical, which means it handles data with clusters nested within each other. The user controls the level in the hierarchy at which clusters are formed.
It is non-parametric, density-based method that does not assume a specific shape or number of clusters. Instead, it automatically finds the clusters based on areas where data points are densely packed together. In other words, it looks for regions of high density (many data points close to each other) and forms clusters around them. This allows it to find clusters of varying shapes and sizes.
HDBSCAN assigns a label of -1 to points that do not have enough neighbors (low density) to be considered part of a cluster or are too far from any dense region (too isolated from core points). They are usually considered to be noise.
Note
If you want more information on how HDBSCAN works, you can refer to the hdbscan documentation or watch this youtube video.
Let’s first illustrate those concepts with a toy dataset generated using the code below. You do not need to understand the details of the data generation process, and instead pay attention to the resulting scatter plot.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
rng = np.random.default_rng(1)
centers = np.array([[-4.8, 2.0], [-3.5, -4.5]])
X_gaussian, _ = make_blobs(
n_samples=[200, 60],
centers=centers,
cluster_std=[1.0, 0.5],
random_state=42,
)
# Two anisotropic blobs
centers = np.array([[1.0, 5.1], [3.0, 0.9]])
X_aniso_base, y_aniso_base = make_blobs(
n_samples=200, centers=centers, random_state=0
)
# Define two different transformations
transformation_0 = np.array([[0.6, -0.6], [-0.4, 0.8]])
transformation_1 = np.array([[1.5, 0], [0, 0.3]])
# Apply different transformations to each blob
X_aniso = np.copy(X_aniso_base)
X_aniso[y_aniso_base == 0] = np.dot(
X_aniso_base[y_aniso_base == 0], transformation_0
)
X_aniso[y_aniso_base == 1] = np.dot(
X_aniso_base[y_aniso_base == 1], transformation_1
)
def make_wavy_blob(n_samples, shift=0.0, noise=0.2, freq=3):
"Make wavy blobs in feature space"
x = np.linspace(-3, 3, n_samples)
y = np.sin(freq * x) + shift
x += rng.normal(scale=noise, size=n_samples)
y += rng.normal(scale=noise, size=n_samples)
return np.vstack((x, y)).T
X_wave1 = make_wavy_blob(100, shift=4.7, freq=1)
transformation = np.array([[0.6, -0.6], [0.4, 0.8]])
X_wave1 = np.dot(X_wave1, transformation)
X_wave2 = make_wavy_blob(200, shift=-2.0, freq=2)
X_noise = rng.uniform(low=-8, high=8, size=(100, 2)) # background noise
X_all = np.vstack((X_gaussian, X_aniso, X_wave1, X_wave2, X_noise))
plt.scatter(X_all[:, 0], X_all[:, 1], alpha=0.6)
_ = plt.title("Synthetic dataset")
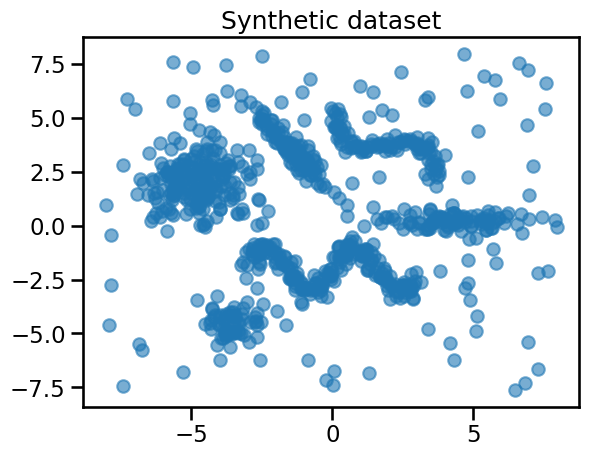
You can observe that the dataset contains:
four Gaussian blobs with different sizes and densities, some of which are elongated and other more spherical;
two non-convex clusters with wavy shapes;
a background noise of points uniformly distributed in the feature space.
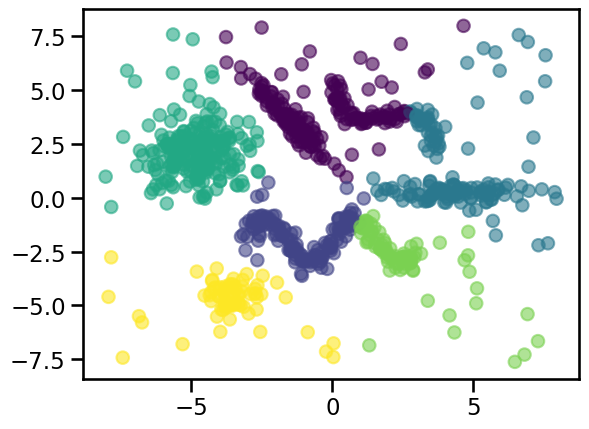
Let’s first try to find a cluster structure using K-means with 6 clusters to match our data generating process.
from sklearn.cluster import KMeans
cluster_labels = KMeans(n_clusters=6, random_state=0).fit_predict(X_all)
_ = plt.scatter(X_all[:, 0], X_all[:, 1], c=cluster_labels, alpha=0.6)
We could try to increase the number of clusters to avoid grouping unrelated points in the same cluster:
cluster_labels = KMeans(n_clusters=10, random_state=0).fit_predict(X_all)
_ = plt.scatter(X_all[:, 0], X_all[:, 1], c=cluster_labels, alpha=0.6)
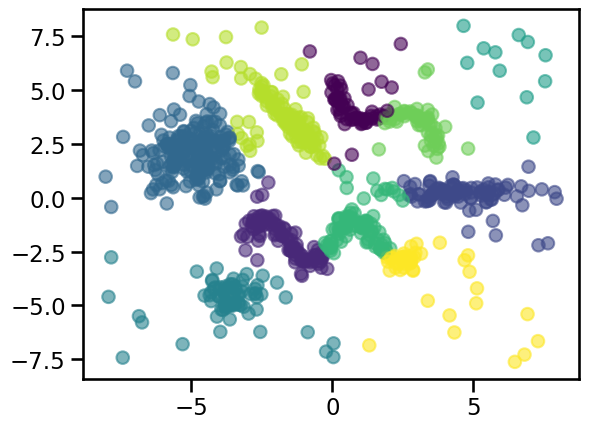
However, we can observe this cluster assignment divides the high density regions while also grouping unrelated points together. Furthermore, the background noise data points are always assigned to the nearest centroids and thus treated as cluster members. Therefore, adjusting the number of clusters is not enough to get good results in this kind of data.
We can compute the silhouette score for this number of clusters and keep it in mind for the moment.
from sklearn.metrics import silhouette_score
kmeans_score = silhouette_score(X_all, cluster_labels)
print(f"Silhouette score for k-means clusters: {kmeans_score:.3f}")
Silhouette score for k-means clusters: 0.472
Let’s now repeat the experiment using HDBSCAN instead. For this clustering
technique, the most important hyperparameter is min_cluster_size, which
controls the minimum number of samples for a group to be considered a cluster;
groupings smaller than this size are considered as noise.
from sklearn.cluster import HDBSCAN
cluster_labels = HDBSCAN(min_cluster_size=10).fit_predict(X_all)
_ = plt.scatter(X_all[:, 0], X_all[:, 1], c=cluster_labels, alpha=0.6)

The clusters found using HDBSCAN better match our intuition of how data points should be grouped. We can compute the corresponding silhouette score:
hdbscan_score = silhouette_score(X_all, cluster_labels)
print(f"Silhouette score for HDBSCAN clusters: {hdbscan_score:.3f}")
Silhouette score for HDBSCAN clusters: 0.383
Notice that this score is lower than the score using k-means, even if HDBSCAN
seems to do a better job when grouping the data points. The reason here is
that points considered as noise (labeled with -1 by HDBSCAN) do not follow a
cluster-like structure. We can test that hypothesis as follows:
mask = cluster_labels != -1 # mask is TRUE for entries that are NOT -1
cluster_labels_filtered = cluster_labels[mask]
X_all_filtered = X_all[mask]
hdbscan_score = silhouette_score(X_all_filtered, cluster_labels_filtered)
print(
f"Silhouette score for HDBSCAN clusters without noise: {hdbscan_score:.3f}"
)
Silhouette score for HDBSCAN clusters without noise: 0.516
In this case we do obtain a better silhouette score, but in general we do not suggest dropping samples labeled as noise.
Also, keep in mind that HDBSCAN does not optimize intra- or inter-cluster distances, which are the basis of the silhouette score. It is then more appropriate to use the silhouette score when clusters are compact and roughly convex. Otherwise, if the clusters are elongated, wavy, or even wrap around other clusters, comparing average distances becomes less meaningful.
Clustering of geospatial data#
Let’s now apply HDBSCAN to a more realistic use-case: the geospatial columns of the California Housing Dataset.
from sklearn.datasets import fetch_california_housing
data, target = fetch_california_housing(return_X_y=True, as_frame=True)
target *= 100 # rescale the target in k$
We can use plotly to first visualize the housing prices across the state of California.
import plotly.express as px
def plot_map(df, color_feature, colorbar_label="cluster label"):
fig = px.scatter_map(
df,
lat="Latitude",
lon="Longitude",
color=color_feature,
zoom=5,
height=600,
labels={"color": colorbar_label},
)
fig.update_layout(
mapbox_style="open-street-map",
mapbox_center={
"lat": df["Latitude"].mean(),
"lon": df["Longitude"].mean(),
},
margin={"r": 0, "t": 0, "l": 0, "b": 0},
)
return fig.show(renderer="notebook")
fig = plot_map(data, target, colorbar_label="price (k$)")
We can try to use K-means to group data points into different spatial regions (irrespective of the housing prices) and visualize the results on a map.
Note that the Geospatial columns are Latitude and Longitude are already
on the same scale so there is no need to standardize them before clustering.
from sklearn.cluster import KMeans
geo_columns = ["Latitude", "Longitude"]
geo_data = data[geo_columns]
kmeans = KMeans(n_clusters=20, random_state=0)
cluster_labels = kmeans.fit_predict(geo_data)
cluster_labels
array([1, 1, 1, ..., 3, 3, 3], dtype=int32)
fig = plot_map(data, cluster_labels.astype("str"))
We can observe that results are really influenced by the fact that K-means favors spherical-shaped clusters. Let’s try again with HDBSCAN which should not suffer from the same bias.
from sklearn.cluster import HDBSCAN
hdbscan = HDBSCAN(min_cluster_size=100)
cluster_labels = hdbscan.fit_predict(geo_data)
cluster_labels
array([18, 18, 18, ..., -1, -1, -1])
fig = plot_map(data, cluster_labels.astype("str"))
HDBSCAN automatically detects highly populated areas that match urban centers,
potentially increasing the housing prices. In addition we observe that points
lying in low density regions are labeled -1 instead of being forced into a
cluster.
The number of resulting clusters is a consequence of the choice of
min_cluster_size:
print(f"Number of clusters: {len(np.unique(cluster_labels))}")
Number of clusters: 22
Decreasing min_cluster_size increases the number of clusters:
hdbscan = HDBSCAN(min_cluster_size=30)
cluster_labels = hdbscan.fit_predict(geo_data)
fig = plot_map(data, cluster_labels.astype("str"))
print(f"Number of clusters: {len(np.unique(cluster_labels))}")
Number of clusters: 63
We previously mentioned that the user can control the level in the hierarchy
at which clusters are formed. This can be done without retraining the model by
using the dbscan_clustering method, and is an indirect way to control the
number of clusters:
for cut_distance in [0.1, 0.3, 0.5]:
cluster_labels = hdbscan.dbscan_clustering(
cut_distance=cut_distance, min_cluster_size=30
)
plot_map(data, cluster_labels.astype("str"))
print(f"Number of clusters: {len(np.unique(cluster_labels))}")
Number of clusters: 29
Number of clusters: 6
Number of clusters: 3
Concluding remarks#
In this notebook we have introduced HDBSCAN, a clustering technique that allows for non-convex clusters and does not require the user to specify the number of clusters.
Keep in mind however, that despite its flexibility, even HDBSCAN can still fail to find relevant clusters in some datasets: sometimes there is no meaningful cluster structure in the data.