📃 Solution for Exercise M4.04#
In the previous Module we tuned the hyperparameter C of the logistic
regression without mentioning that it controls the regularization strength.
Later, on the slides on 🎥 Intuitions on regularized linear models we
mentioned that a small C provides a more regularized model, whereas a
non-regularized model is obtained with an infinitely large value of C.
Indeed, C behaves as the inverse of the alpha coefficient in the Ridge
model.
In this exercise, we ask you to train a logistic regression classifier using
different values of the parameter C to find its effects by yourself.
We start by loading the dataset. We only keep the Adelie and Chinstrap classes to keep the discussion simple.
Note
If you want a deeper overview regarding this dataset, you can refer to the Appendix - Datasets description section at the end of this MOOC.
import pandas as pd
penguins = pd.read_csv("../datasets/penguins_classification.csv")
penguins = (
penguins.set_index("Species").loc[["Adelie", "Chinstrap"]].reset_index()
)
culmen_columns = ["Culmen Length (mm)", "Culmen Depth (mm)"]
target_column = "Species"
from sklearn.model_selection import train_test_split
penguins_train, penguins_test = train_test_split(
penguins, random_state=0, test_size=0.4
)
data_train = penguins_train[culmen_columns]
data_test = penguins_test[culmen_columns]
target_train = penguins_train[target_column]
target_test = penguins_test[target_column]
We define a function to help us fit a given model and plot its decision
boundary. We recall that by using a DecisionBoundaryDisplay with diverging
colormap, vmin=0 and vmax=1, we ensure that the 0.5 probability is mapped
to the white color. Equivalently, the darker the color, the closer the
predicted probability is to 0 or 1 and the more confident the classifier is in
its predictions.
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.inspection import DecisionBoundaryDisplay
def plot_decision_boundary(model):
model.fit(data_train, target_train)
accuracy = model.score(data_test, target_test)
C = model.get_params()["logisticregression__C"]
disp = DecisionBoundaryDisplay.from_estimator(
model,
data_train,
response_method="predict_proba",
plot_method="pcolormesh",
cmap="RdBu_r",
alpha=0.8,
vmin=0.0,
vmax=1.0,
)
DecisionBoundaryDisplay.from_estimator(
model,
data_train,
response_method="predict_proba",
plot_method="contour",
linestyles="--",
linewidths=1,
alpha=0.8,
levels=[0.5],
ax=disp.ax_,
)
sns.scatterplot(
data=penguins_train,
x=culmen_columns[0],
y=culmen_columns[1],
hue=target_column,
palette=["tab:blue", "tab:red"],
ax=disp.ax_,
)
plt.legend(bbox_to_anchor=(1.05, 0.8), loc="upper left")
plt.title(f"C: {C} \n Accuracy on the test set: {accuracy:.2f}")
Let’s now create our predictive model.
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
logistic_regression = make_pipeline(StandardScaler(), LogisticRegression())
Influence of the parameter C on the decision boundary#
Given the following candidates for the C parameter and the
plot_decision_boundary function, find out the impact of C on the
classifier’s decision boundary.
How does the value of
Cimpact the confidence on the predictions?How does it impact the underfit/overfit trade-off?
How does it impact the position and orientation of the decision boundary?
Try to give an interpretation on the reason for such behavior.
Cs = [1e-6, 0.01, 0.1, 1, 10, 100, 1e6]
# solution
for C in Cs:
logistic_regression.set_params(logisticregression__C=C)
plot_decision_boundary(logistic_regression)
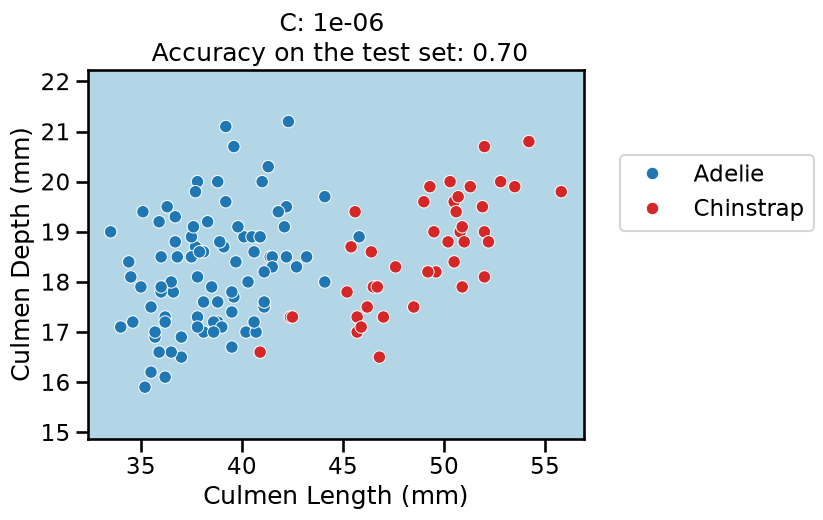
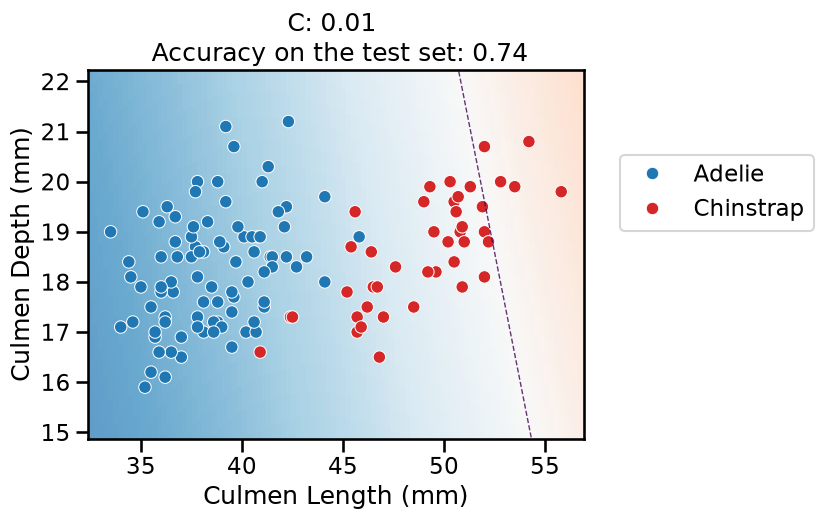
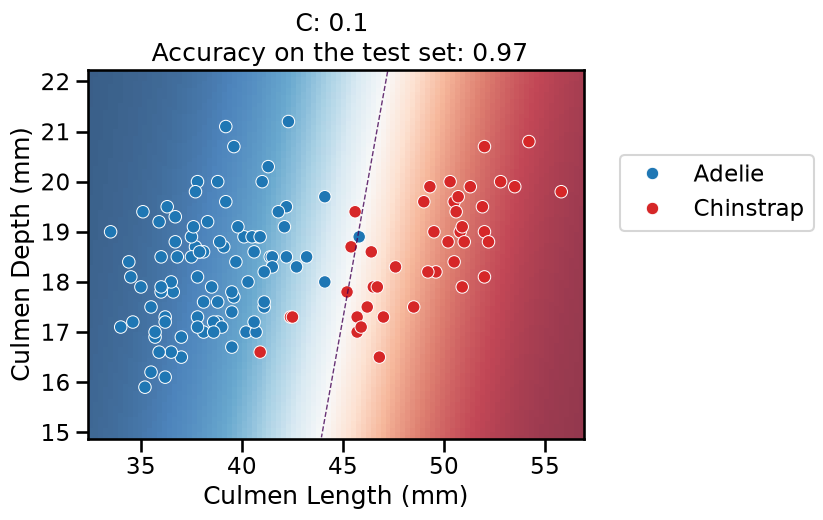
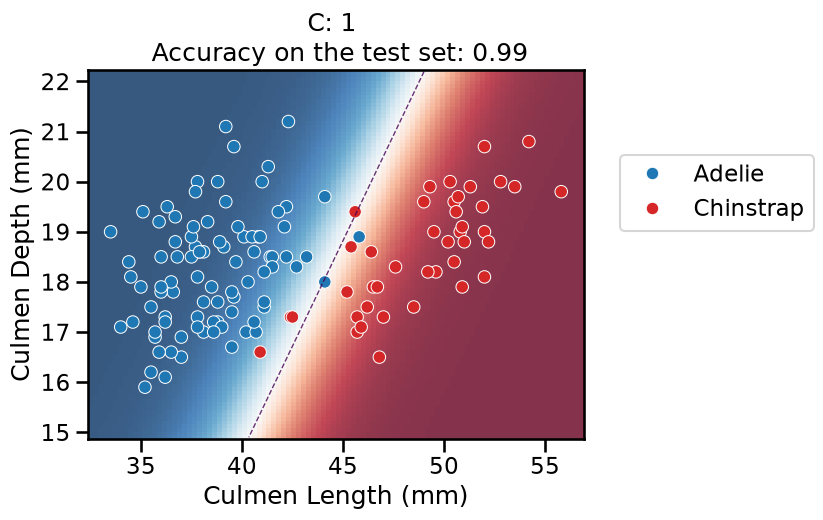
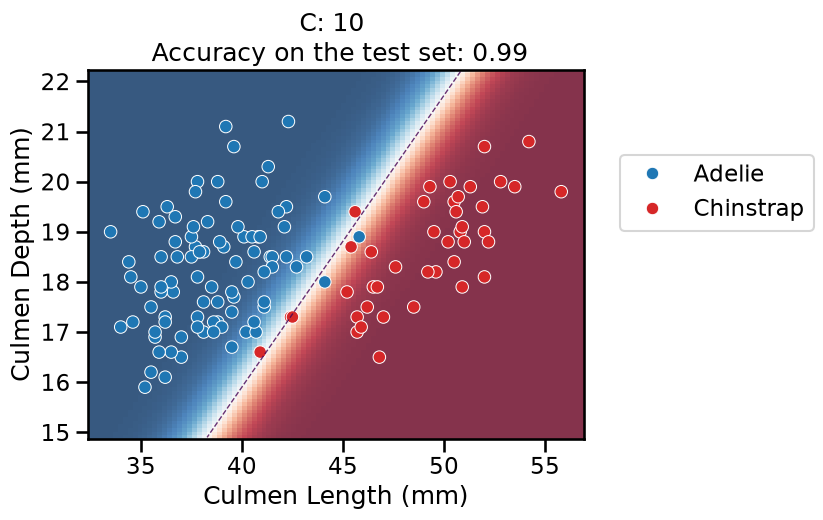
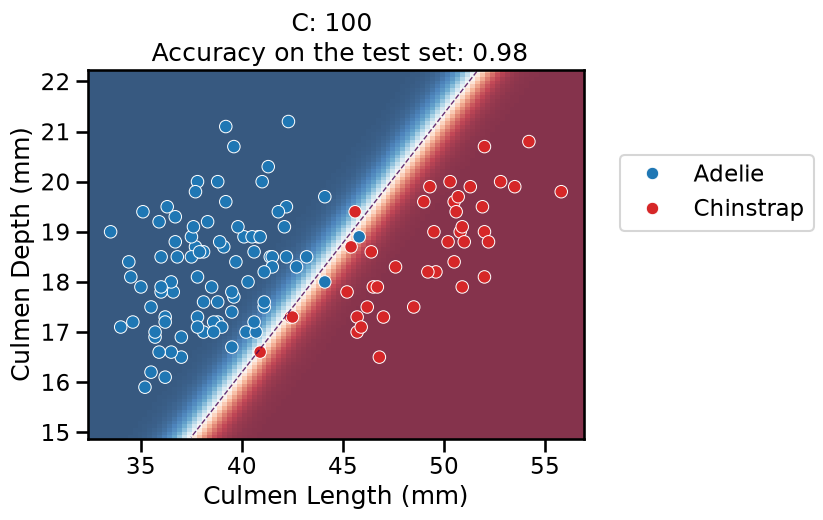
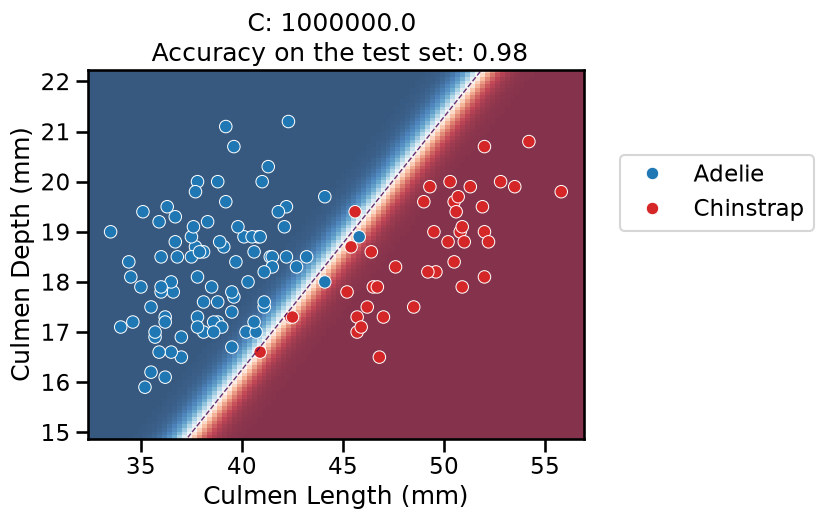
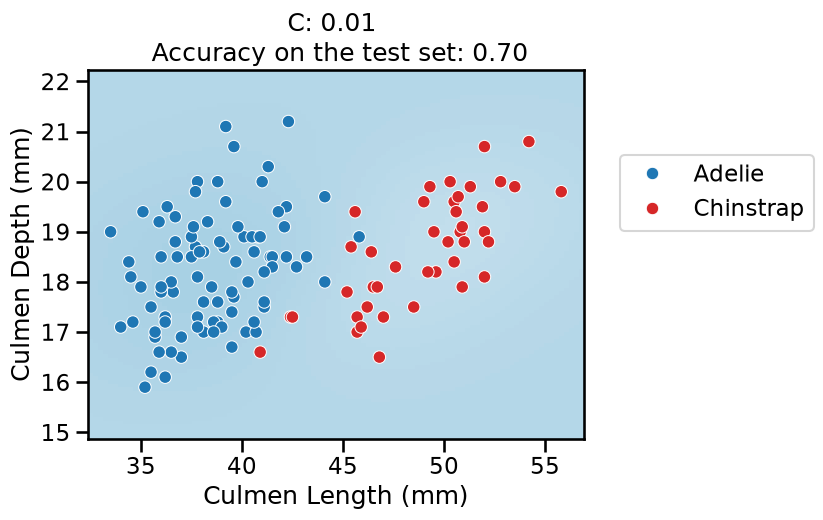
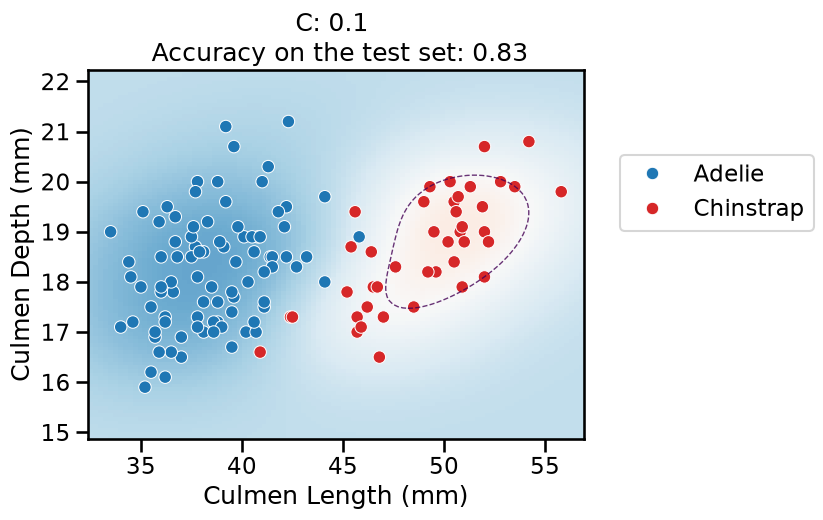
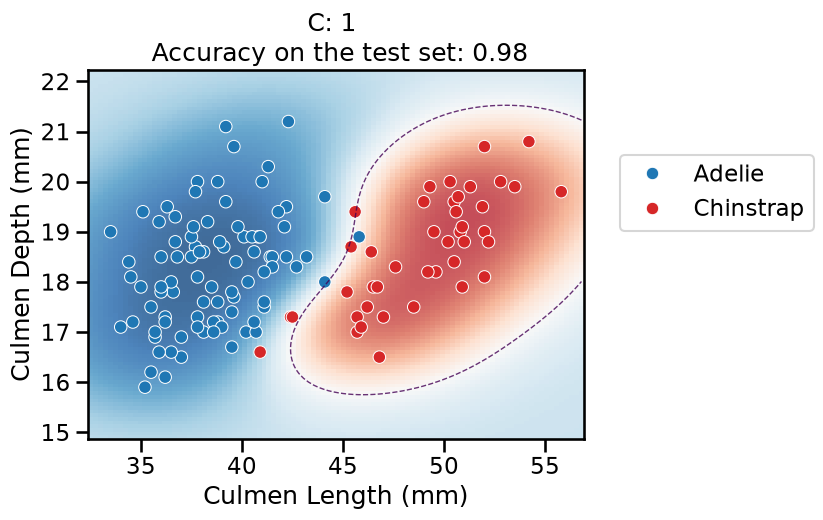
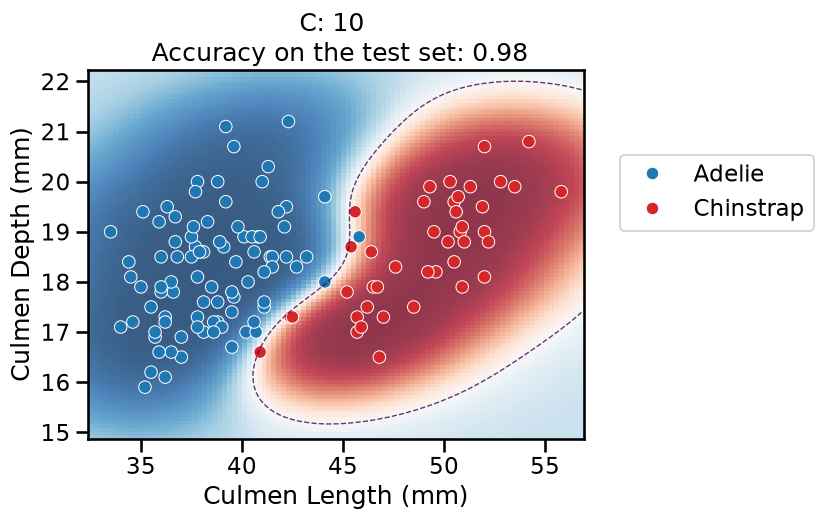
On this series of plots we can observe several important points. Regarding the confidence on the predictions:
For low values of
C(strong regularization), the classifier is less confident in its predictions. We are enforcing a spread sigmoid.For high values of
C(weak regularization), the classifier is more confident: the areas with dark blue (very confident in predicting “Adelie”) and dark red (very confident in predicting “Chinstrap”) nearly cover the entire feature space. We are enforcing a steep sigmoid.
To answer the next question, think that misclassified data points are more costly when the classifier is more confident on the decision. Decision rules are mostly driven by avoiding such cost. From the previous observations we can then deduce that:
The smaller the
C(the stronger the regularization), the lower the cost of a misclassification. As more data points lay in the low-confidence zone, the more the decision rules are influenced almost uniformly by all the data points. This leads to a less expressive model, which may underfit.The higher the value of
C(the weaker the regularization), the more the decision is influenced by a few training points very close to the boundary, where decisions are costly. Remember that models may overfit if the number of samples in the training set is too small, as at least a minimum of samples is needed to average the noise out.
The orientation is the result of two factors: minimizing the number of misclassified training points with high confidence and their distance to the decision boundary (notice how the contour line tries to align with the most misclassified data points in the dark-colored zone). This is closely related to the value of the weights of the model, which is explained in the next part of the exercise.
Finally, for small values of C the position of the decision boundary is
affected by the class imbalance: when C is near zero, the model predicts the
majority class (as seen in the training set) everywhere in the feature space.
In our case, there are approximately two times more “Adelie” than “Chinstrap”
penguins. This explains why the decision boundary is shifted to the right when
C gets smaller. Indeed, the most regularized model predicts light blue
almost everywhere in the feature space.
Impact of the regularization on the weights#
Look at the impact of the C hyperparameter on the magnitude of the weights.
Hint: You can access pipeline
steps
by name or position. Then you can query the attributes of that step such as
coef_.
# solution
lr_weights = []
for C in Cs:
logistic_regression.set_params(logisticregression__C=C)
logistic_regression.fit(data_train, target_train)
coefs = logistic_regression[-1].coef_[0]
lr_weights.append(pd.Series(coefs, index=culmen_columns))
lr_weights = pd.concat(lr_weights, axis=1, keys=[f"C: {C}" for C in Cs])
lr_weights.plot.barh()
_ = plt.title("LogisticRegression weights depending of C")
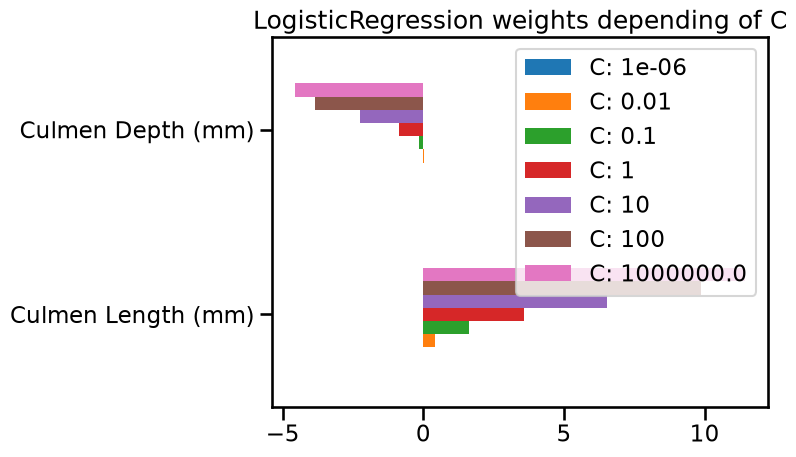
As small C provides a more regularized model, it shrinks the weights values
toward zero, as in the Ridge model.
In particular, with a strong penalty (e.g. C = 0.01), the weight of the feature
named “Culmen Depth (mm)” is almost zero. It explains why the decision
separation in the plot is almost perpendicular to the “Culmen Length (mm)”
feature.
For even stronger penalty strengths (e.g. C = 1e-6), the weights of both
features are almost zero. It explains why the decision separation in the plot
is almost constant in the feature space: the predicted probability is only
based on the intercept parameter of the model (which is never regularized).
Impact of the regularization on with non-linear feature engineering#
Use the plot_decision_boundary function to repeat the experiment using a
non-linear feature engineering pipeline. For such purpose, insert
Nystroem(kernel="rbf", gamma=1, n_components=100) between the
StandardScaler and the LogisticRegression steps.
Does the value of
Cstill impact the position of the decision boundary and the confidence of the model?What can you say about the impact of
Con the underfitting vs overfitting trade-off?
from sklearn.kernel_approximation import Nystroem
# solution
classifier = make_pipeline(
StandardScaler(),
Nystroem(kernel="rbf", gamma=1.0, n_components=100, random_state=0),
LogisticRegression(max_iter=1000),
)
for C in Cs:
classifier.set_params(logisticregression__C=C)
plot_decision_boundary(classifier)
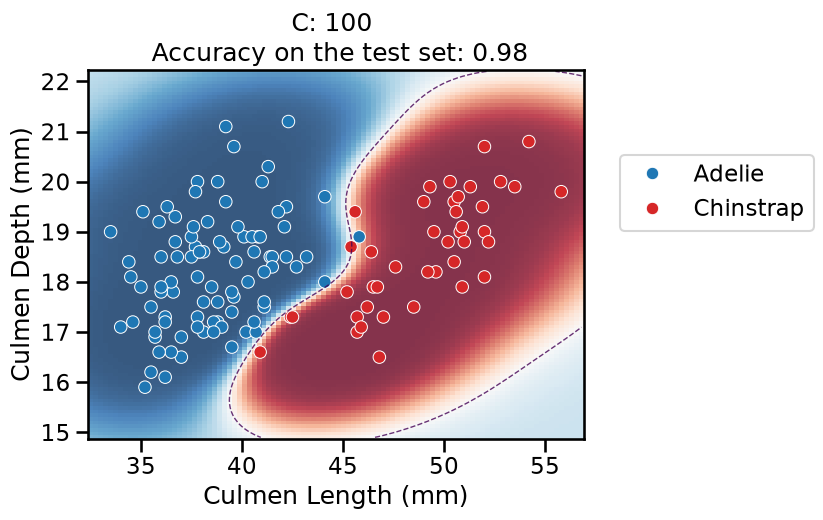
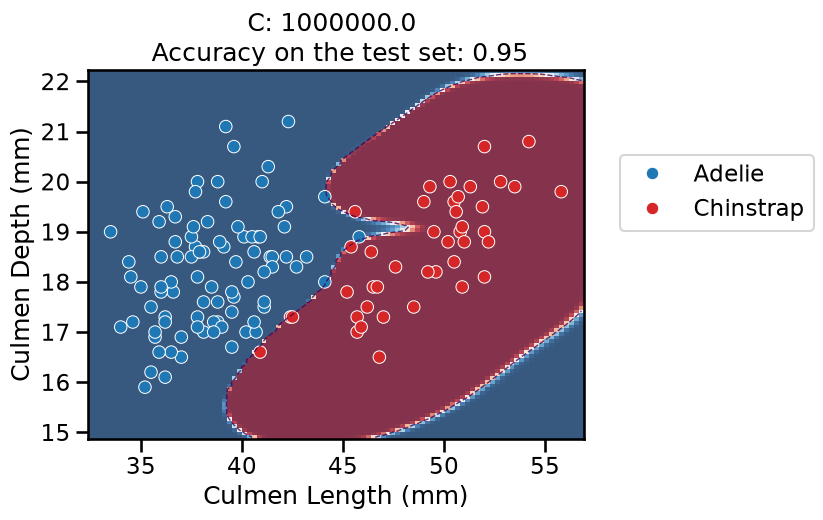
For the lowest values of
C, the overall pipeline underfits: it predicts the majority class everywhere, as previously.When
Cincreases, the models starts to predict some datapoints from the “Chinstrap” class but the model is not very confident anywhere in the feature space.The decision boundary is no longer a straight line: the linear model is now classifying in the 100-dimensional feature space created by the
Nystroemtransformer. As are result, the decision boundary induced by the overall pipeline is now expressive enough to wrap around the minority class.For
C = 1in particular, it finds a smooth red blob around most of the “Chinstrap” data points. When moving away from the data points, the model is less confident in its predictions and again tends to predict the majority class according to the proportion in the training set.For higher values of
C, the model starts to overfit: it is very confident in its predictions almost everywhere, but it should not be trusted: the model also makes a larger number of mistakes on the test set (not shown in the plot) while adopting a very curvy decision boundary to attempt fitting all the training points, including the noisy ones at the frontier between the two classes. This makes the decision boundary very sensitive to the sampling of the training set and as a result, it does not generalize well in that region. This is confirmed by the (slightly) lower accuracy on the test set.
Finally, we can also note that the linear model on the raw features was as good or better than the best model using non-linear feature engineering. So in this case, we did not really need this extra complexity in our pipeline. Simpler is better!
So to conclude, when using non-linear feature engineering, it is often
possible to make the pipeline overfit, even if the original feature space is
low-dimensional. As a result, it is important to tune the regularization
parameter in conjunction with the parameters of the transformers (e.g. tuning
gamma would be important here). This has a direct impact on the certainty of
the predictions.