Non-linear feature engineering for Linear Regression#
In this notebook, we show that even if linear models are not natively adapted
to express a target that is not a linear function of the data, it is still
possible to make linear models more expressive by engineering additional
features.
A machine learning pipeline that combines a non-linear feature engineering step followed by a linear regression step can therefore be considered a non-linear regression model as a whole.
In this occasion we are not loading a dataset, but creating our own custom data consisting of a single feature. The target is built as a cubic polynomial on said feature. To make things a bit more challenging, we add some random fluctuations to the target.
import numpy as np
rng = np.random.RandomState(0)
n_sample = 100
data_max, data_min = 1.4, -1.4
len_data = data_max - data_min
# sort the data to make plotting easier later
data = np.sort(rng.rand(n_sample) * len_data - len_data / 2)
noise = rng.randn(n_sample) * 0.3
target = data**3 - 0.5 * data**2 + noise
Tip
np.random.RandomState allows creating a random number generator which can
be later used to get deterministic results.
To ease the plotting, we create a pandas dataframe containing the data and target:
import pandas as pd
full_data = pd.DataFrame({"input_feature": data, "target": target})
import seaborn as sns
_ = sns.scatterplot(
data=full_data, x="input_feature", y="target", color="black", alpha=0.5
)
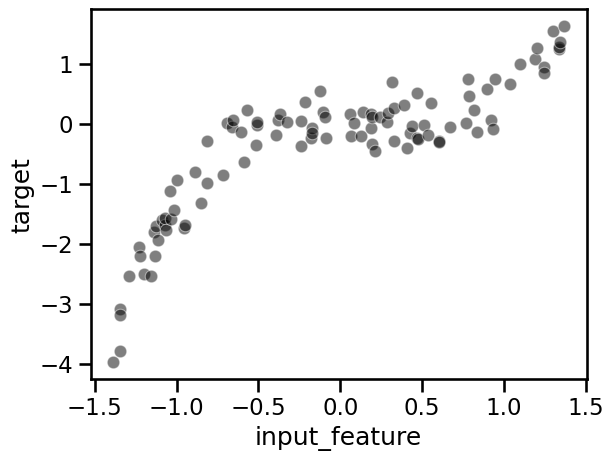
Warning
In scikit-learn, by convention data (also called X in the scikit-learn
documentation) should be a 2D matrix of shape (n_samples, n_features).
If data is a 1D vector, you need to reshape it into a matrix with a
single column if the vector represents a feature or a single row if the
vector represents a sample.
# X should be 2D for sklearn: (n_samples, n_features)
data = data.reshape((-1, 1))
data.shape
(100, 1)
To avoid writing the same code in multiple places we define a helper function that fits, scores and plots the different regression models.
from sklearn.metrics import mean_squared_error
def fit_score_plot_regression(model, title=None):
model.fit(data, target)
target_predicted = model.predict(data)
mse = mean_squared_error(target, target_predicted)
ax = sns.scatterplot(
data=full_data, x="input_feature", y="target", color="black", alpha=0.5
)
ax.plot(data, target_predicted)
if title is not None:
_ = ax.set_title(title + f" (MSE = {mse:.2f})")
else:
_ = ax.set_title(f"Mean squared error = {mse:.2f}")
We now observe the limitations of fitting a linear regression model.
from sklearn.linear_model import LinearRegression
linear_regression = LinearRegression()
linear_regression
LinearRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LinearRegression()
fit_score_plot_regression(linear_regression, title="Simple linear regression")
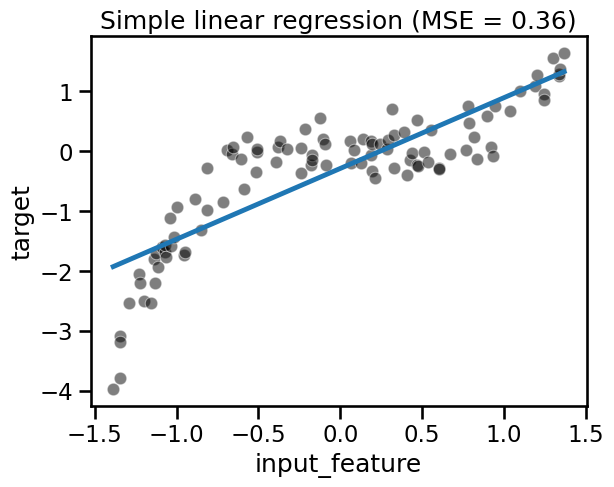
Here the coefficient and intercept learnt by LinearRegression define the
best “straight line” that fits the data. We can inspect the coefficients using
the attributes of the model learnt as follows:
print(
f"weight: {linear_regression.coef_[0]:.2f}, "
f"intercept: {linear_regression.intercept_:.2f}"
)
weight: 1.18, intercept: -0.29
Notice that the learnt model cannot handle the non-linear relationship between
data and target because linear models assume a linear relationship.
Indeed, there are 3 possibilities to solve this issue:
choose a model that can natively deal with non-linearity,
engineer a richer set of features by including expert knowledge which can be directly used by a simple linear model, or
use a “kernel” to have a locally-based decision function instead of a global linear decision function.
Let’s illustrate quickly the first point by using a decision tree regressor which can natively handle non-linearity.
from sklearn.tree import DecisionTreeRegressor
tree = DecisionTreeRegressor(max_depth=3).fit(data, target)
tree
DecisionTreeRegressor(max_depth=3)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
DecisionTreeRegressor(max_depth=3)
fit_score_plot_regression(tree, title="Decision tree regression")
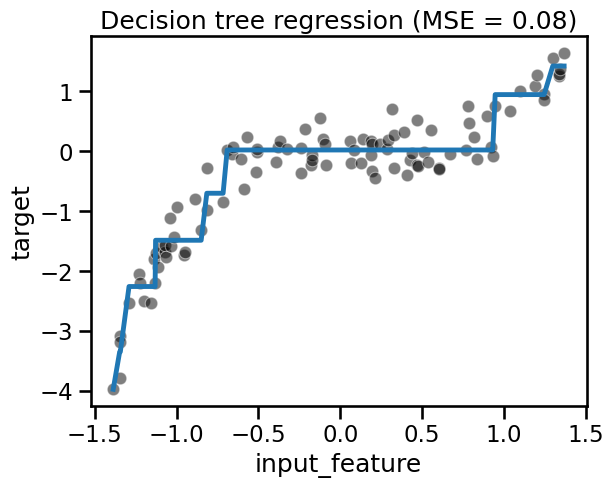
Instead of having a model which can natively deal with non-linearity, we could
also modify our data: we could create new features, derived from the original
features, using some expert knowledge. In this example, we know that we have a
cubic and squared relationship between data and target (because we
generated the data).
Indeed, we could create two new features (data ** 2 and data ** 3) using
this information as follows. This kind of transformation is called a
polynomial feature expansion:
data.shape
(100, 1)
data_expanded = np.concatenate([data, data**2, data**3], axis=1)
data_expanded.shape
(100, 3)
Instead of manually creating such polynomial features one could directly use sklearn.preprocessing.PolynomialFeatures.
from sklearn.preprocessing import PolynomialFeatures
polynomial_expansion = PolynomialFeatures(degree=3, include_bias=False)
In the previous cell we had to set include_bias=False as otherwise we would
create a constant feature perfectly correlated to the intercept_ introduced
by the LinearRegression. We can verify that this procedure is equivalent to
creating the features by hand up to numerical error by computing the maximum
of the absolute values of the differences between the features generated by
both methods and checking that it is close to zero:
np.abs(polynomial_expansion.fit_transform(data) - data_expanded).max()
np.float64(2.220446049250313e-16)
To demonstrate the use of the PolynomialFeatures class, we use a
scikit-learn pipeline which first transforms the features and then fit the
regression model.
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures
polynomial_regression = make_pipeline(
PolynomialFeatures(degree=3, include_bias=False),
LinearRegression(),
)
polynomial_regression
Pipeline(steps=[('polynomialfeatures',
PolynomialFeatures(degree=3, include_bias=False)),
('linearregression', LinearRegression())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('polynomialfeatures',
PolynomialFeatures(degree=3, include_bias=False)),
('linearregression', LinearRegression())])PolynomialFeatures(degree=3, include_bias=False)
LinearRegression()
fit_score_plot_regression(polynomial_regression, title="Polynomial regression")
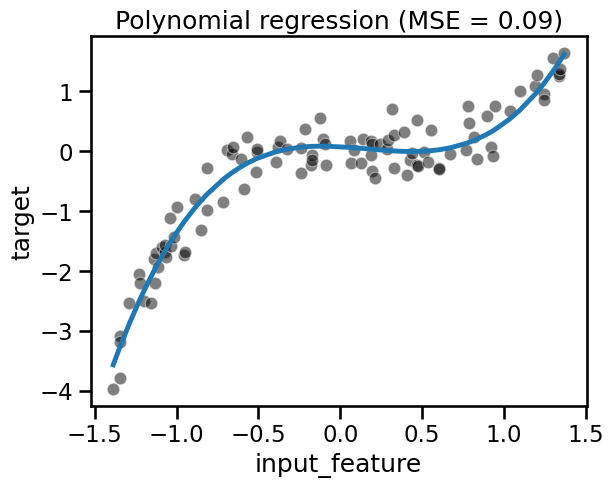
We can see that even with a linear model, we can overcome the linearity limitation of the model by adding the non-linear components in the design of additional features. Here, we created new features by knowing the way the target was generated.
The last possibility is to make a linear model more expressive is to use a “kernel”. Instead of learning one weight per feature as we previously did, a weight is assigned to each sample. However, not all samples are used: some redundant data points of the training set are assigned a weight of 0 so that they do no influence the model’s prediction function. This is the main intuition of the support vector machine algorithm.
The mathematical definition of “kernels” and “support vector machines” is beyond the scope of this course. We encourage interested readers with a mathematical training to have a look at the scikit-learn documentation on SVMs for more details.
For the rest of us, let us just develop some intuitions on the relative expressive power of support vector machines with linear and non-linear kernels by fitting them on the same dataset.
First, consider a support vector machine with a linear kernel:
from sklearn.svm import SVR
svr = SVR(kernel="linear")
svr
SVR(kernel='linear')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
SVR(kernel='linear')
fit_score_plot_regression(svr, title="Linear support vector machine")
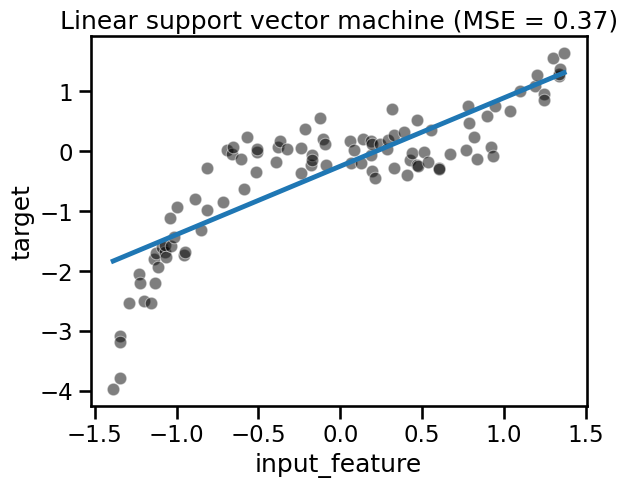
The predictions of our SVR with a linear kernel are all aligned on a straight
line. SVR(kernel="linear") is indeed yet another example of a linear model.
The estimator can also be configured to use a non-linear kernel. Then, it can learn a prediction function that computes non-linear relations between samples for which we want to make a prediction and selected samples from the training set.
The result is another kind of non-linear regression model with a similar expressivity as our previous polynomial regression pipeline:
svr = SVR(kernel="poly", degree=3)
svr
SVR(kernel='poly')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
SVR(kernel='poly')
fit_score_plot_regression(svr, title="Polynomial support vector machine")
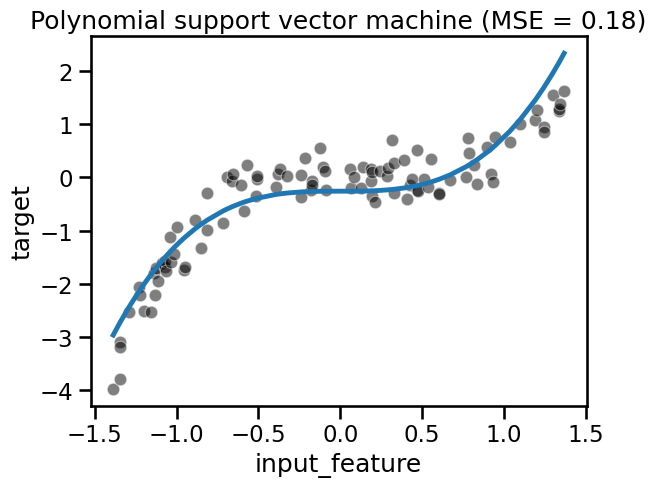
Kernel methods such as SVR are very efficient for small to medium datasets.
For larger datasets with n_samples >> 10_000, it is often computationally
more efficient to perform explicit feature expansion using
PolynomialFeatures or other non-linear transformers from scikit-learn such
as
KBinsDiscretizer
or
SplineTransformer.
Here again we refer the interested reader to the documentation to get a proper definition of those methods. The following just gives an intuitive overview of the predictions we would get using those on our toy dataset:
from sklearn.preprocessing import KBinsDiscretizer
binned_regression = make_pipeline(
KBinsDiscretizer(n_bins=8),
LinearRegression(),
)
binned_regression
Pipeline(steps=[('kbinsdiscretizer', KBinsDiscretizer(n_bins=8)),
('linearregression', LinearRegression())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('kbinsdiscretizer', KBinsDiscretizer(n_bins=8)),
('linearregression', LinearRegression())])KBinsDiscretizer(n_bins=8)
LinearRegression()
fit_score_plot_regression(binned_regression, title="Binned regression")
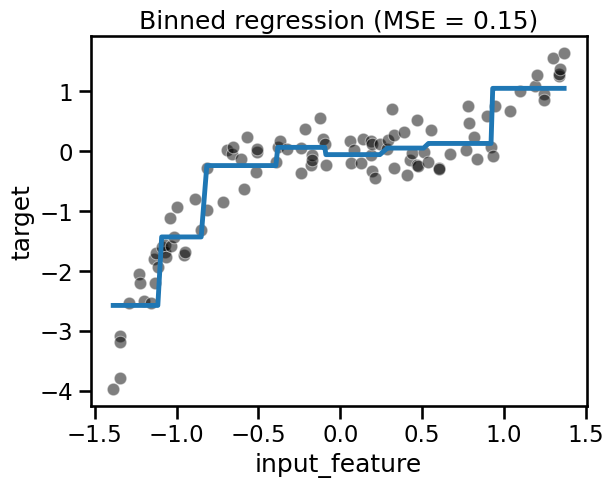
from sklearn.preprocessing import SplineTransformer
spline_regression = make_pipeline(
SplineTransformer(degree=3, include_bias=False),
LinearRegression(),
)
spline_regression
Pipeline(steps=[('splinetransformer', SplineTransformer(include_bias=False)),
('linearregression', LinearRegression())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('splinetransformer', SplineTransformer(include_bias=False)),
('linearregression', LinearRegression())])SplineTransformer(include_bias=False)
LinearRegression()
fit_score_plot_regression(spline_regression, title="Spline regression")
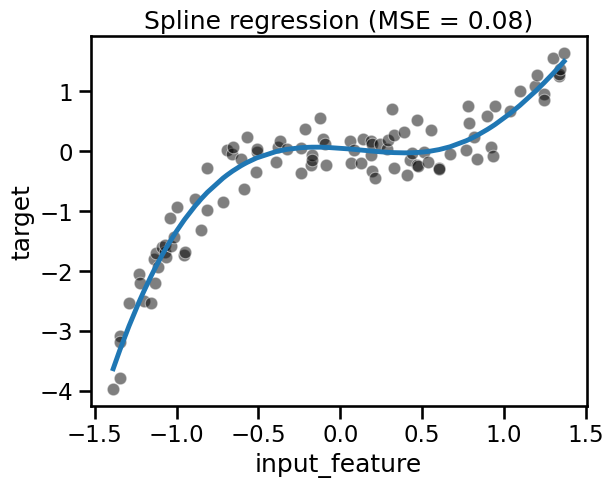
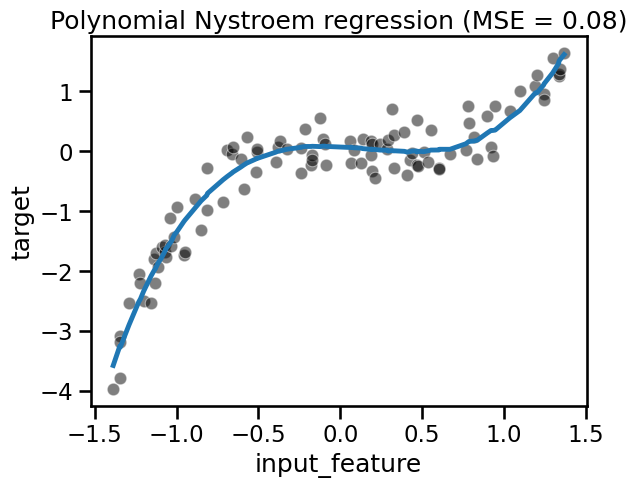
Nystroem is a nice alternative to PolynomialFeatures that makes it
possible to keep the memory usage of the transformed dataset under control.
However, interpreting the meaning of the intermediate features can be
challenging.
from sklearn.kernel_approximation import Nystroem
nystroem_regression = make_pipeline(
Nystroem(kernel="poly", degree=3, n_components=5, random_state=0),
LinearRegression(),
)
nystroem_regression
Pipeline(steps=[('nystroem',
Nystroem(degree=3, kernel='poly', n_components=5,
random_state=0)),
('linearregression', LinearRegression())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('nystroem',
Nystroem(degree=3, kernel='poly', n_components=5,
random_state=0)),
('linearregression', LinearRegression())])Nystroem(degree=3, kernel='poly', n_components=5, random_state=0)
LinearRegression()
fit_score_plot_regression(
nystroem_regression, title="Polynomial Nystroem regression"
)
Notebook Recap#
In this notebook we explored several ways to expand a single numerical feature into several non-linearly derived new features. This makes our machine learning pipeline more expressive and less likely to underfit, even if the last stage of the pipeline is a simple linear regression model.
For the sake of simplicity, we introduced those transformers on a toy regression problem with a single input feature. However, non-linear feature transformers such as Nystroem can further improve the expressiveness of machine learning pipelines to model non-linear interactions between features. We will explore this possibility in the next exercise.