Overfit-generalization-underfit#
In the previous notebook, we presented the general cross-validation framework and how it helps us quantify the training and testing errors as well as their fluctuations.
In this notebook, we put these two errors into perspective and show how they can help us know if our model generalizes, overfits, or underfits.
Let’s first load the data and create the same model as in the previous notebook.
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing(as_frame=True)
data, target = housing.data, housing.target
target *= 100 # rescale the target in k$
Note
If you want a deeper overview regarding this dataset, you can refer to the Appendix - Datasets description section at the end of this MOOC.
from sklearn.tree import DecisionTreeRegressor
regressor = DecisionTreeRegressor()
Overfitting vs. underfitting#
To better understand the generalization performance of our model and maybe
find insights on how to improve it, we compare the testing error with the
training error. Thus, we need to compute the error on the training set, which
is possible using the cross_validate function.
import pandas as pd
from sklearn.model_selection import cross_validate, ShuffleSplit
cv = ShuffleSplit(n_splits=30, test_size=0.2, random_state=0)
cv_results = cross_validate(
regressor,
data,
target,
cv=cv,
scoring="neg_mean_absolute_error",
return_train_score=True,
n_jobs=2,
)
cv_results = pd.DataFrame(cv_results)
The cross-validation used the negative mean absolute error. We transform the negative mean absolute error into a positive mean absolute error.
scores = pd.DataFrame()
scores[["train error", "test error"]] = -cv_results[
["train_score", "test_score"]
]
import matplotlib.pyplot as plt
scores.plot.hist(bins=50, edgecolor="black")
plt.xlabel("Mean absolute error (k$)")
_ = plt.title("Train and test errors distribution via cross-validation")
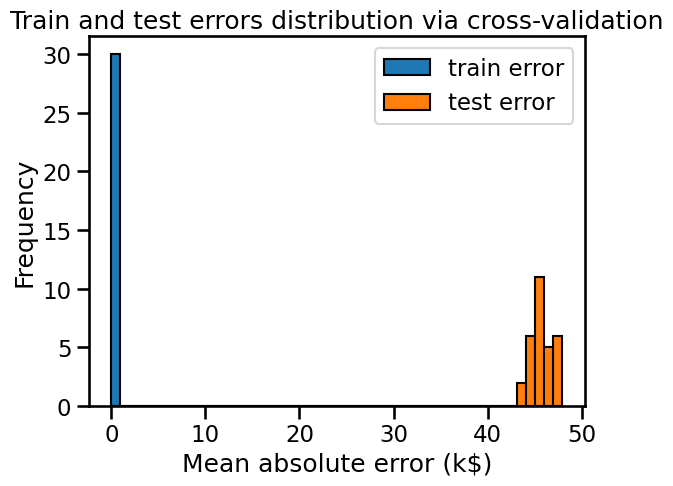
By plotting the distribution of the training and testing errors, we get information about whether our model is over-fitting, under-fitting (or both at the same time).
Here, we observe a small training error (actually zero), meaning that the model is not under-fitting: it is flexible enough to capture any variations present in the training set.
However the significantly larger testing error tells us that the model is over-fitting: the model has memorized many variations of the training set that could be considered “noisy” because they do not generalize to help us make good prediction on the test set.
Validation curve#
We call hyperparameters those parameters that potentially impact the result of the learning and subsequent predictions of a predictor. For example:
the number of neighbors in a k-nearest neighbor model;
the degree of the polynomial.
Some model hyperparameters are usually the key to go from a model that underfits to a model that overfits, hopefully going through a region were we can get a good balance between the two. We can acquire knowledge by plotting a curve called the validation curve. This curve can also be applied to the above experiment and varies the value of a hyperparameter.
For the decision tree, the max_depth hyperparameter is used to control the
tradeoff between under-fitting and over-fitting.
%%time
import numpy as np
from sklearn.model_selection import ValidationCurveDisplay
max_depth = np.array([1, 5, 10, 15, 20, 25])
disp = ValidationCurveDisplay.from_estimator(
regressor,
data,
target,
param_name="max_depth",
param_range=max_depth,
cv=cv,
scoring="neg_mean_absolute_error",
negate_score=True,
std_display_style="errorbar",
n_jobs=2,
)
_ = disp.ax_.set(
xlabel="Maximum depth of decision tree",
ylabel="Mean absolute error (k$)",
title="Validate curve for decision tree",
)
CPU times: user 366 ms, sys: 21.4 ms, total: 388 ms
Wall time: 10.7 s
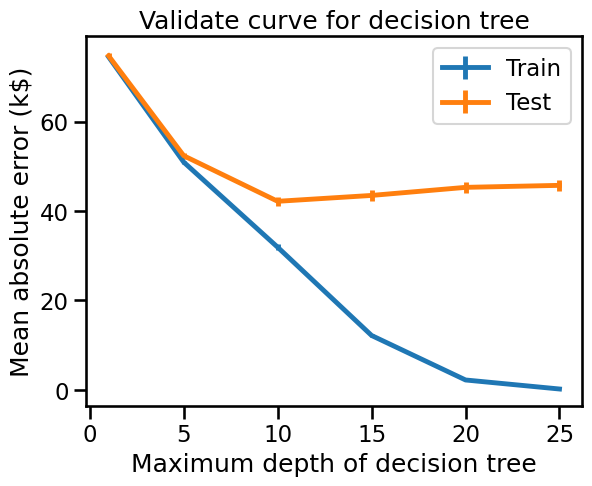
The validation curve can be divided into three areas:
For
max_depth < 10, the decision tree underfits. The training error and therefore the testing error are both high. The model is too constrained and cannot capture much of the variability of the target variable.The region around
max_depth = 10corresponds to the parameter for which the decision tree generalizes the best. It is flexible enough to capture a fraction of the variability of the target that generalizes, while not memorizing all of the noise in the target.For
max_depth > 10, the decision tree overfits. The training error becomes very small, while the testing error increases. In this region, the models create decisions specifically for noisy samples harming its ability to generalize to test data.
Note that for max_depth = 10, the model overfits a bit as there is a gap
between the training error and the testing error. It can also potentially
underfit also a bit at the same time, because the training error is still far
from zero (more than 30 k$), meaning that the model might still be too
constrained to model interesting parts of the data. However, the testing error
is minimal, and this is what really matters. This is the best compromise we
could reach by just tuning this parameter.
Be aware that looking at the mean errors is quite limiting. We should also
look at the standard deviation to assess the dispersion of the score. For such
purpose, we can use the parameter std_display_style to show the standard
deviation of the errors as well. In this case, the variance of the errors is
small compared to their respective values, and therefore the conclusions above
are quite clear. This is not necessarily always the case.
What is noise?#
In this notebook, we talked about the fact that datasets can contain noise.
There can be several kinds of noises, among which we can identify:
measurement imprecision from a physical sensor (e.g. temperature);
reporting errors by human collectors.
Those unpredictable data acquisition errors can happen either on the input features or in the target variable (in which case we often name this label noise).
In practice, the most common source of “noise” is not necessarily a real noise, but rather the absence of the measurement of a relevant feature.
Consider the following example: when predicting the price of a house, the surface area will surely impact the price. However, the price will also be influenced by whether the seller is in a rush and decides to sell the house below the market price. A model will be able to make predictions based on the former but not the latter, so “seller’s rush” is a source of noise since it won’t be present in the features.
Since this missing/unobserved feature is randomly varying from one sample to the next, it appears as if the target variable was changing because of the impact of a random perturbation or noise, even if there were no significant errors made during the data collection process (besides not measuring the unobserved input feature).
One extreme case could happen if there where samples in the dataset with exactly the same input feature values but different values for the target variable. That is very unlikely in real life settings, but could be the case if all features are categorical or if the numerical features were discretized or rounded up naively. In our example, we can imagine two houses having the exact same features in our dataset, but having different prices because of the (unmeasured) seller’s rush.
Apart from this extreme case, it’s hard to know for sure what should qualify or not as noise and which kind of “noise” as introduced above is dominating. But in practice, the best way to make our predictive models robust to noise is to avoid overfitting models by:
selecting models that are simple enough or with tuned hyper-parameters as explained in this module;
collecting a larger number of labeled samples for the training set.
Summary:#
In this notebook, we saw:
how to identify whether a model is generalizing, overfitting, or underfitting;
how to check influence of a hyperparameter on the underfit/overfit tradeoff.